A build by any other name would smell as sweet
To quote from Wikipedia that, in turn, quotes from Technopedia a software build is “the process of converting source code files into standalone software artifact(s)”. Data Scientists often fancy themselves exempt from the art of building software artifacts (as well as a few other software development skills, but that’s a topic for another post), since they write most of their code in a programming language that doesn’t involve compilation of any kind (unless it does).
However, a lot of what Data Scientists do in their jobs fits the definiton of a build to the letter.
Model training is a build. You have source code that describes the architecture of the model and the optimization procedure for training it, a dataset (or, say, a reinforcement learning environment), a set of hyperparameters and, of course, dependencies required for your source code to run. Combine these ingredients on a stove for a few hours (or days) and the result is an artifact in the form of a snapshot of trained model weights.
Same for any other optimization routine or computation. Solving the protein folding problem. Genetic programming. Finding the 45-millions digit of pi.
Even research papers (if you’re the kind of data scientist who writes them) can be viewed as build artifacts:
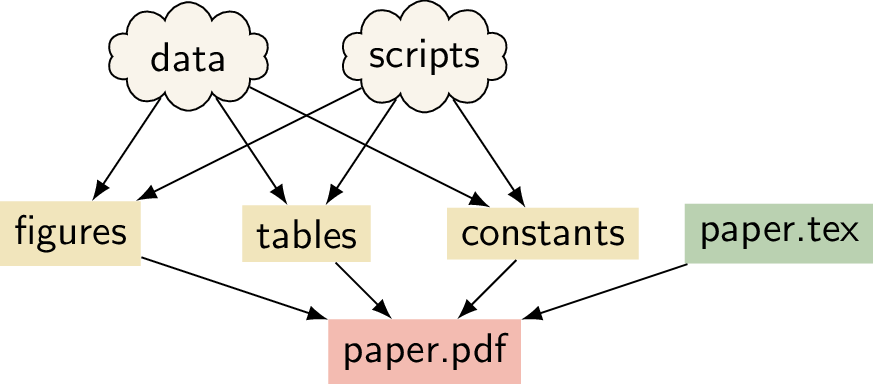
(illustration from a brilliant article on the Turing way)
OK, but… why does this matter?
It matters because the software development community is years ahead of the data science community in terms of best practices and tools for reproducible builds. Data Scientists can save themselves a lot of system administration, script writing, yak-shaving and wheel-reinventing by adopting those.
Some things you can do right now are:
- Start using Makefiles
- Set up a git hook that will retrain the model automatically as soon as you push any changes to its architecture. cirun offers a convinient way to provision hardware for that.
- Read up on MLOps principles and tools that come with them, though keep in mind that most of them are just DevOps principles repackaged for a slightly different audience.
- Come back to this blog for more Data Science advice
Confessions
This work is taxpayer funded