Taxonomy of Automatic Programming
Automatic programming is a pursuit of a seemingly clear goal: let’s make computers program themselves! As usual, that nasty pal of ours is in the details: are compilers automatic programming? They do generate code automatically, and modern compilers tend to utilize sophisticated machine learning to do so [Leather, Cummins]. So, in the interest of unambiguous nomenclature, here’s a brief summary of various tasks that tend to get lumped under the fuzzy umbrella terms of automatic programming and program synthesis.
Generate, test, learn
Both of the terms refer to an attempt to automatically generate a program that matches some form of specification, optionally using a dataset of existing programs. This suggests a three-component architecure:
- a generator that maps specifications to programs, possibly parametrized with some knowledge base that can be tuned
- a tester evaluating the match between a program and it’s specification (known as discriminator in GAN literature [Creswel et al 2018])
- a learner that updates the generator’s knowledge of the problem domain based on the results of the tests
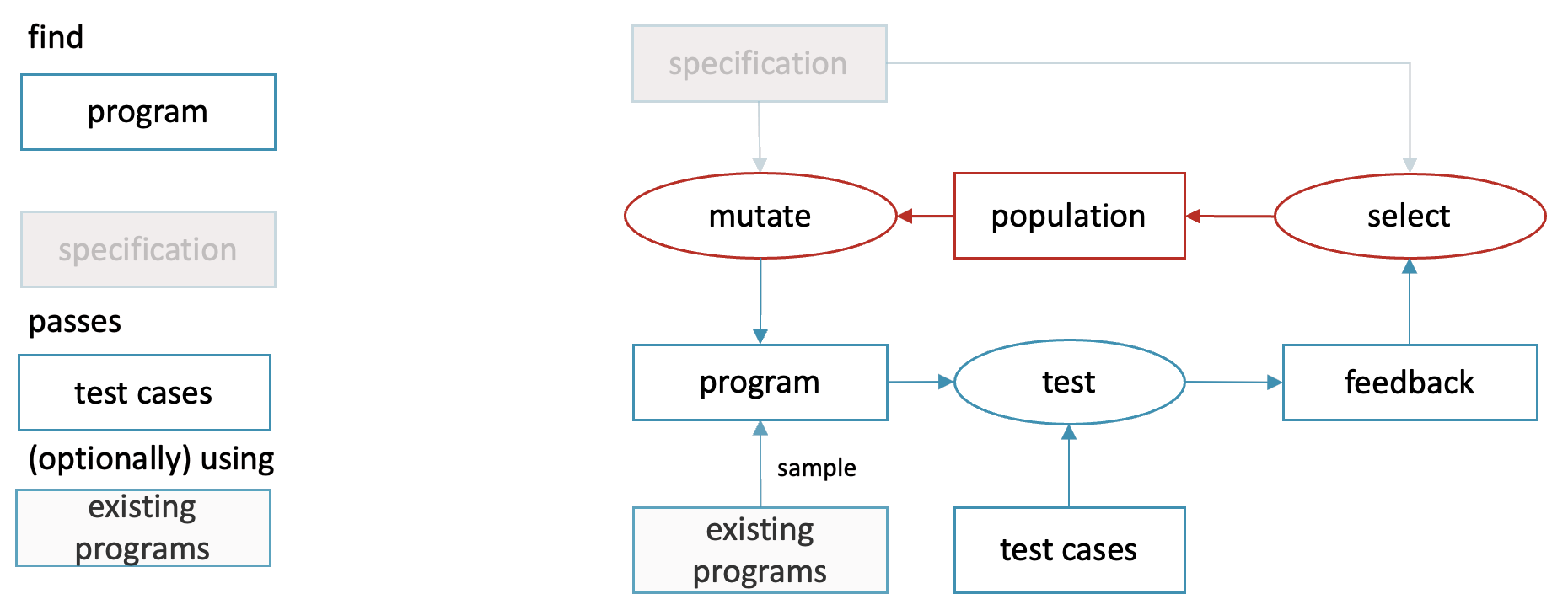
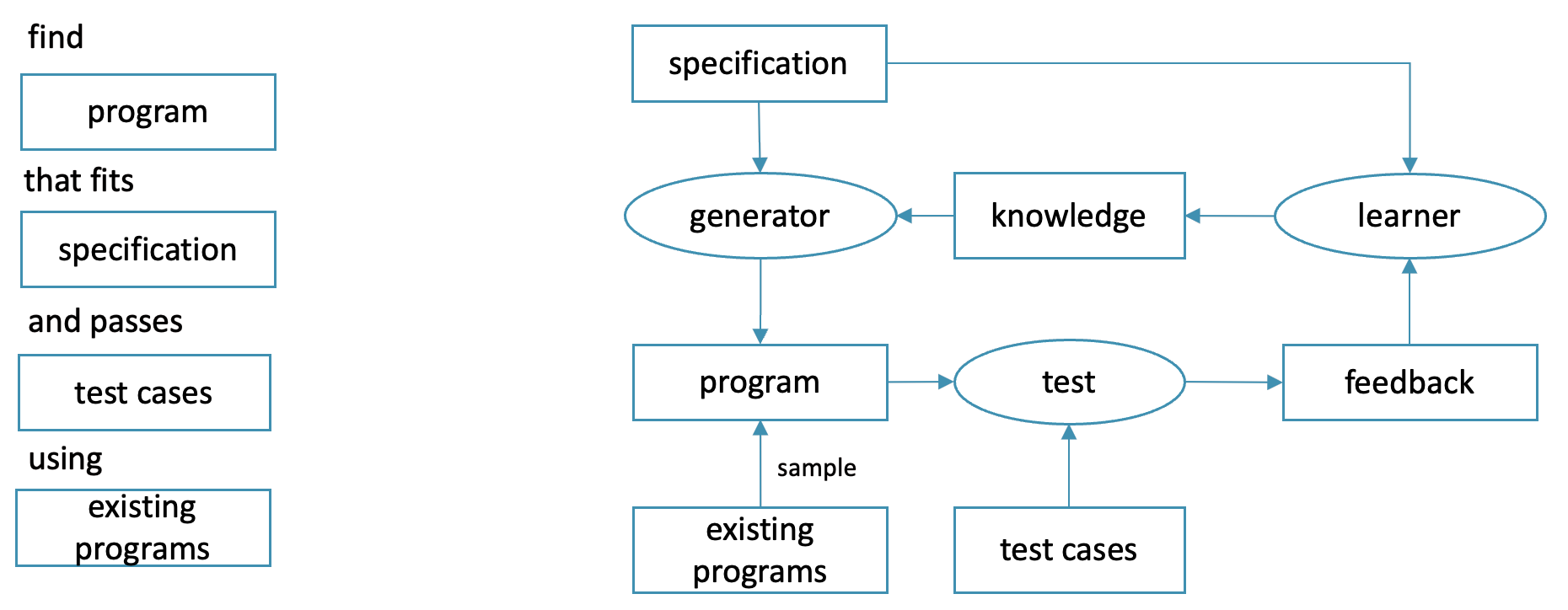 One finds that even superficially unrelated methods end up implementing this same architecture. For instance, in genetic programming [Langdon, Poli 202] there is a family of programs that acts as the generator’s knowledge base, mutation and crossover operators play the role of the generator and selection operator is responsible for learning.
One finds that even superficially unrelated methods end up implementing this same architecture. For instance, in genetic programming [Langdon, Poli 202] there is a family of programs that acts as the generator’s knowledge base, mutation and crossover operators play the role of the generator and selection operator is responsible for learning.
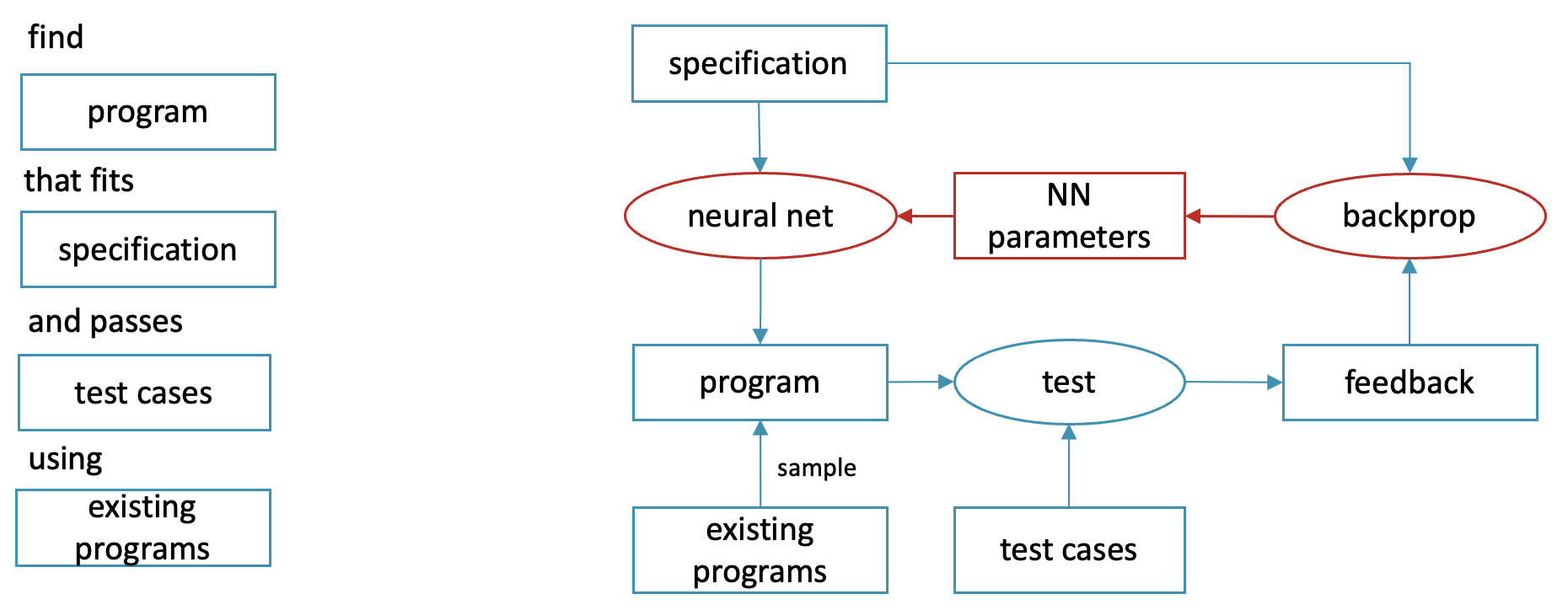
 In neural program synthesis [Kant 2018] generation is done by a parametrized formula, also known as a neural network, the parameters of which are calculated with backpropagation algorithm.
In neural program synthesis [Kant 2018] generation is done by a parametrized formula, also known as a neural network, the parameters of which are calculated with backpropagation algorithm.
 Software development teams with [organic generators] tend to implement similar architecures too, but that’s a discussion for another day.
Software development teams with [organic generators] tend to implement similar architecures too, but that’s a discussion for another day.
But the most ambiguous component of the architecture is definitely specification - what even is that? A text message saying “Make me a todo list app”? A set of formulas describing the methematical conditions [Muggleton 1991, Kreitz 1996] that has to hold for the resulting program (hmmm… specifying that sounds a lot like programming). Hence the most instructive way to classify automatic programming methods is by type of specification.
Code translation
Code translation tasks are all tasks where the specification is a text. We don’t discriminate between natural language texts and machine language texts here: code translation can be both machine language to machine language and natural language to machine language [Yin et al 2018]. machine language to natural language research also exists [Le, Chen and Babar 2020, section 5.1], but is less common and out-of-scope for us anyway.
 Compilers and transpilers are code translation tools, however, they do not include the feedback loop for learning from data: instead, the generator is developed by experts.
Compilers and transpilers are code translation tools, however, they do not include the feedback loop for learning from data: instead, the generator is developed by experts.
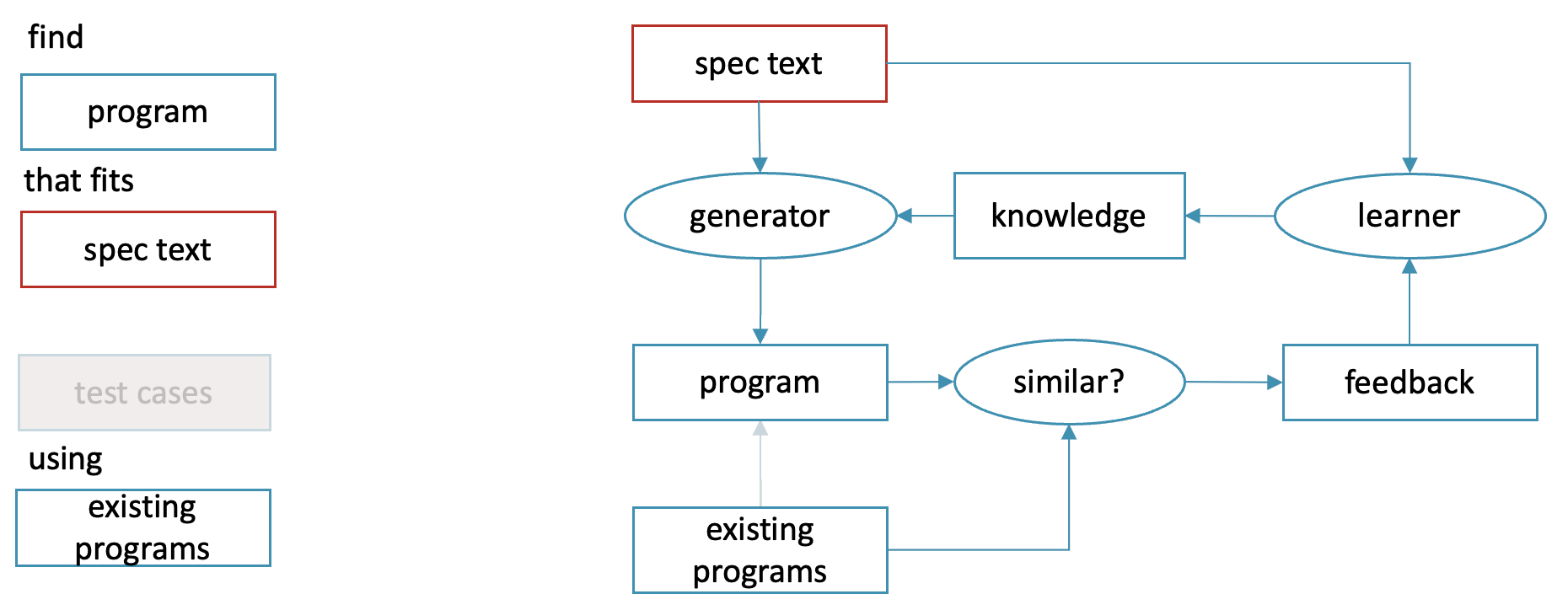
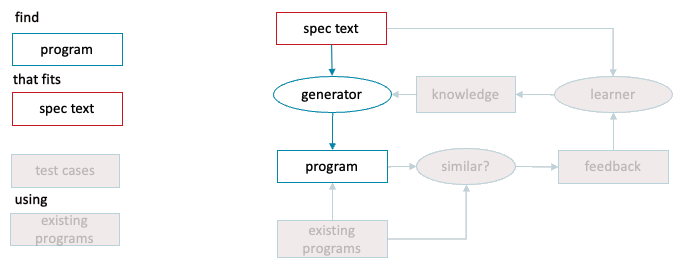 A specific case of code translation is semantic parsing: a subset of natural language to machine language tasks where the natural language contains a comprehensive description of the algorithm to be implemented. So translating “Make me a todo list app” into code is not semantic parsing, but translating a culinary recipe or a boardgame rulebook [Ling et al 2016] or a database query [Yin, Deng et al 2018] into code is.
A specific case of code translation is semantic parsing: a subset of natural language to machine language tasks where the natural language contains a comprehensive description of the algorithm to be implemented. So translating “Make me a todo list app” into code is not semantic parsing, but translating a culinary recipe or a boardgame rulebook [Ling et al 2016] or a database query [Yin, Deng et al 2018] into code is.
Programming by example
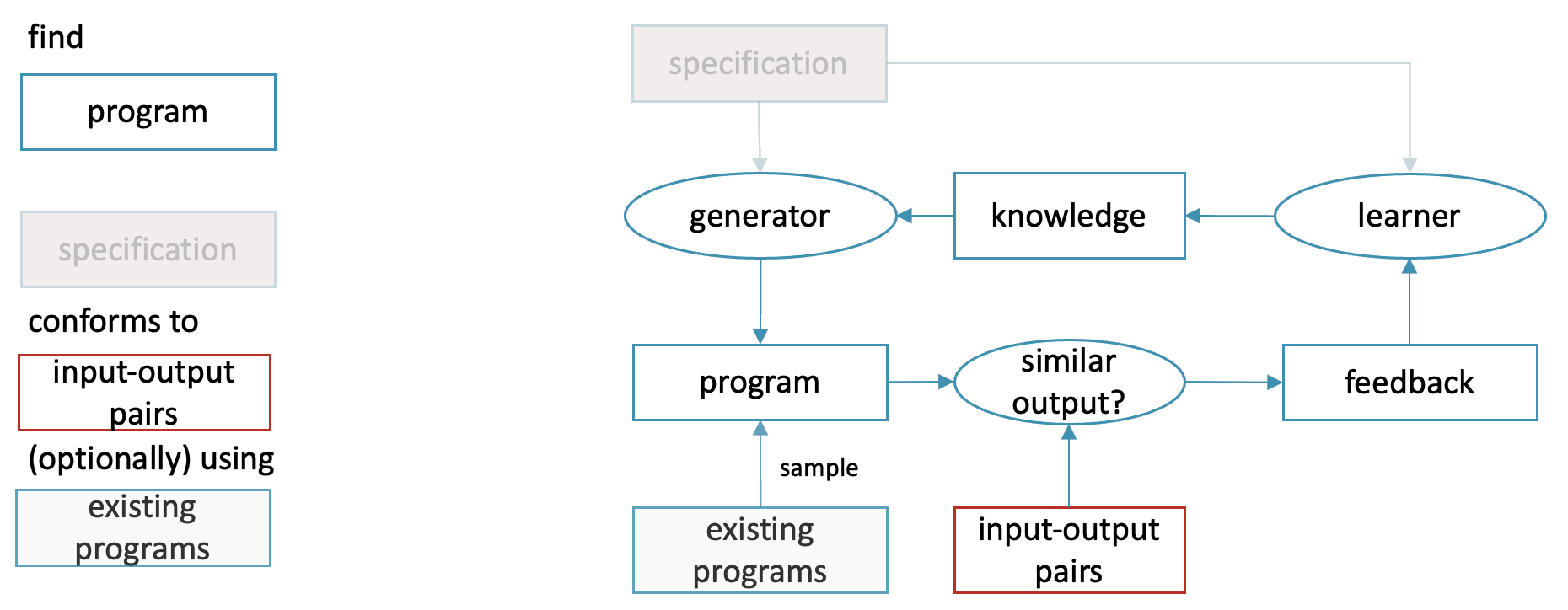
Another approach to specification is specifying the expected output of the program. Or, since in most interesting programs the output depends on the input, input-output pairs. This task is known as programming by example [Halbert 1984, Helmuth and Kelly 2021].
Programmatically Interpretable Reinforcement Learning
But what if tests are specified, but the expected output of the program is not? This is the case in many interactive environments, such as chess: it’s easy to evaluate whether a chess-playing program is doing a good job, but what’s the correct move there? Who knows! Given enough trial and error it’s still possible to generate a correct program with such black box specification, a task known as Programmatically Interpretable Reinforcement Learning [Verma et al 2018].
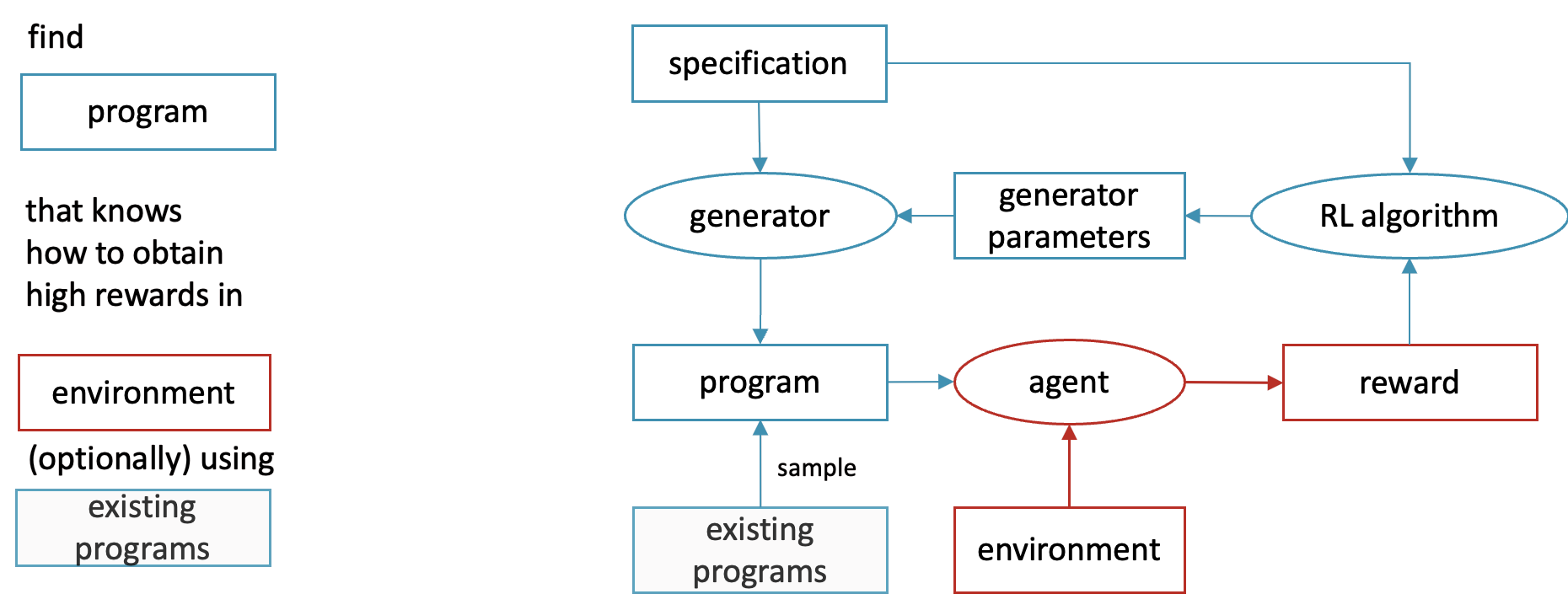 In this setting, a program gets generated and deployed in an environment (typically Paritally Observable Markov Decision Process) that responds with positive and negative rewards. The learning algorithm records what worked and what didn’t and searches the program space for high reward candidates.
In this setting, a program gets generated and deployed in an environment (typically Paritally Observable Markov Decision Process) that responds with positive and negative rewards. The learning algorithm records what worked and what didn’t and searches the program space for high reward candidates.
Language modeling of code
Finally, the trendiest and the most unintuitive of them all. Language modeling is the task of predicting the full text based on how it starts, i.e. the generator takes the first few lines of the program and produces the rest of it.
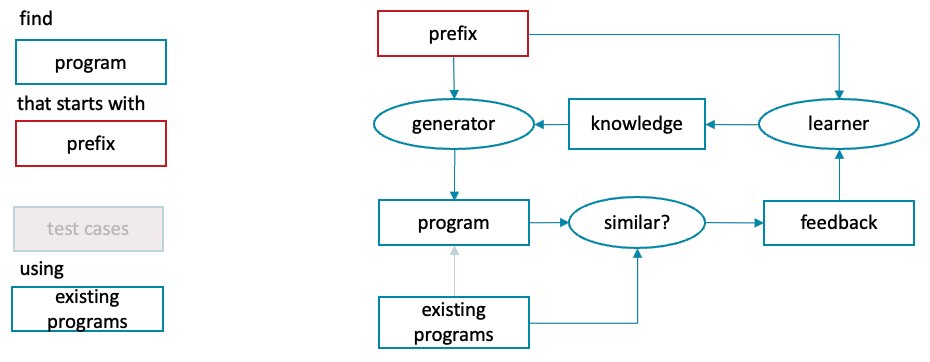 Meticulous readers will notice that language modeling can be viewed as a translation task, translating the beginnings of programs into full programs.
Meticulous readers will notice that language modeling can be viewed as a translation task, translating the beginnings of programs into full programs.
This task is less obvious then others from a practical standpoint. Why do we do this? The short answer comes down to because we can. Reinforcement learning is known to be terribly sample-inefficient while code translation needs less training time, but has to be trained on a parallel corpus: (specification text, expected code output) pairs. The availability of such corpora is limited. For language modeling one needs (prefix, full program) pairs and the prefix can always be extracted from the full program. Thus any corpus of programs is a good dataset for language modeling of code and unlike (other forms of) program translation this task is not bottlenecked by data. Unsurprisingly, this is the task in which the most impressive results have been achieved [Chen et al 2021, Cassano et al 2022].
And there are creative ways to reduce the other (more practical) tasks to the (better solved) task of language modeling. For example, there is a convention in many programming languages to start an implementation of a component with a comment or a docstring in English describing what this component should do. As a result, language models can do natural language to machine language translation simply by extending the prefix:
/*
THE PROGRAM BELOW DOES X, Y and Z
*/
Outroduction
Hope this summary puts the buzzwords of the research literature into perspective. Stay tuned for the funding acknoledgment.
Confessions
This review was written with EU taxpayer support